The Ultimate Glossary of 3D Asset and Scene Generation Models (Jan. 2023)

Thanks to text-to-image models like CLIP, DALL-E, and Stable Diffusion, as well as unicorns like Midjourney, 2022, we have seen an explosion in human creativity. 2022 was only the trailer for what was to come in 2023. If you are a researcher, entrepreneur, or futurist, you want to keep a close eye on the upcoming 3D models. How games, VFX, film production, and the metaverse are made is about to change significantly. The next unicorn lies in one or several of the models in this article. The main challenge with developing 3-D A.I. models is that there isn’t enough data. Existing 3-D datasets are much smaller than 2-D datasets and have less variation.
I thank Scy from our team at Seyhan Lee for helping me create The Ultimate Glossary of Text-to-3D Generative A.I. Models (Jan. 2023).
I made sure to include examples with pictures whenever I could — so that your one-scroll-down experience would be more enjoyable. Save this article, mark it as a favorite, or put it under your pillow so it can always be within reach.
Here goes nothing…
Godbless,
Pinar
Open-source
Text2Mesh
Just like Clip Matrix, text2mesh uses a base mesh that can be changed and textured by using a text prompt.
Clip Matrix
https://arxiv.org/pdf/2109.12922.pdf
This paper by Nikolay Jetchev has a very special place in my heart. Not only is he an extraordinary human being, but we have also been looking into ways to advance and commercialize Clip Matrix since the early days of his experiments in 2021 before he released the paper later in 2022. I can attest that Nikolay was experimenting with text-to-3D creations; before 90% of the models in this article were published.

CLIP-Mesh

CLIP Forge (Autodesk)
Stable-dreamfusion (based on Google’s DreamFusion)
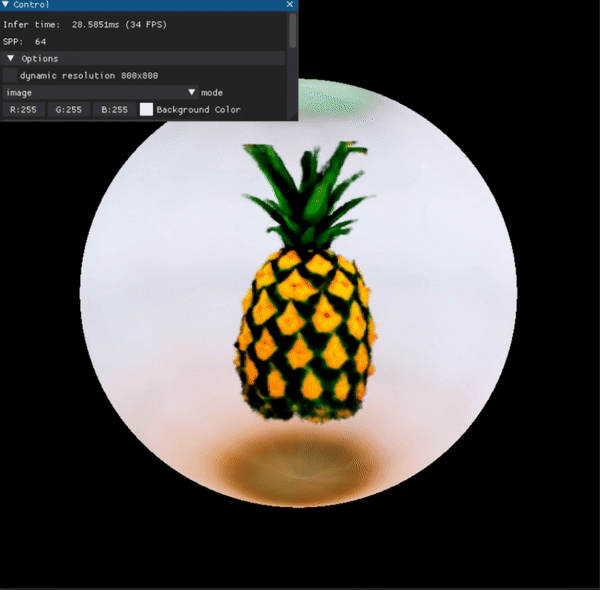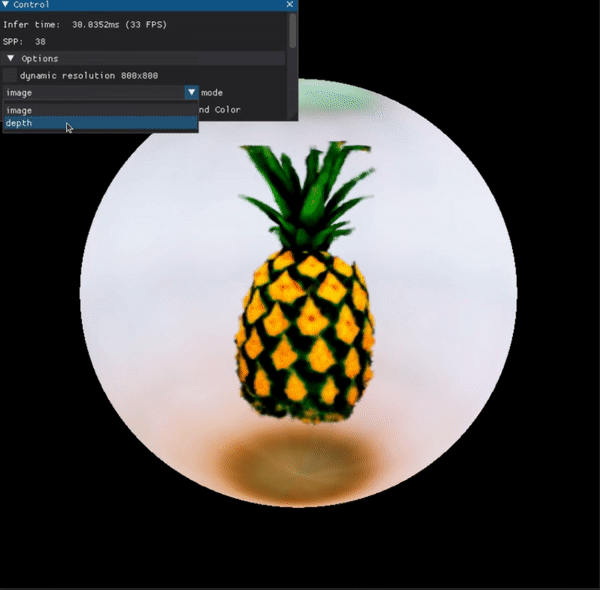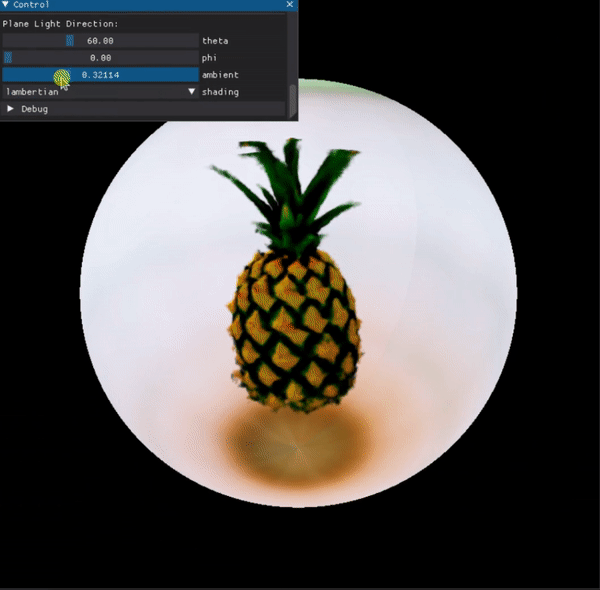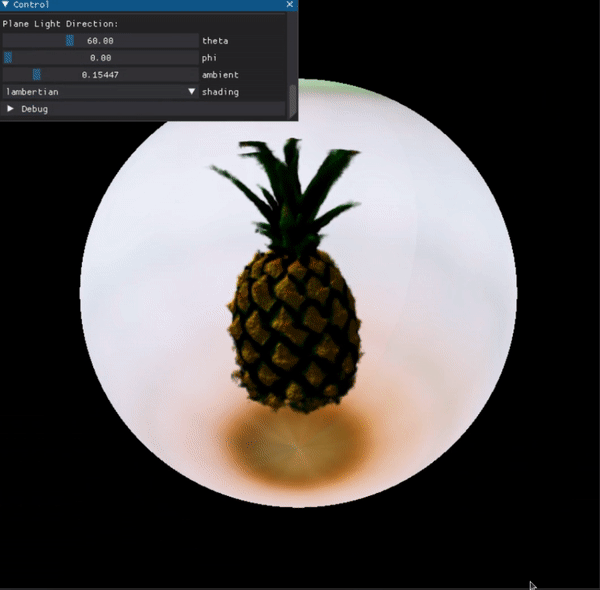
Point-E (OpenAI)
This model turns a caption into a point cloud, which is a step along the way to making high-quality 3-D meshes. When imported into a 3-D program, it still needs to be converted, but it does so much faster than most text-to-3-D models.

GET3D (Nvidia)

Dreamfields (Google)

Gaudi (Apple)
MDM: Human Motion Diffusion Model

Closed tools
Imagine 3D (Luma AI)
Luma is currently offering early access to their models. So far, based on the results they showcase on their website, the fidelity is on the high side compared to other models.
Magic3D (Nvidia)
https://deepimagination.cc/Magic3D/
This model is one of the more advanced ones on the list due to its additional functionalities. You can edit the output with text and use an image input to guide the output.

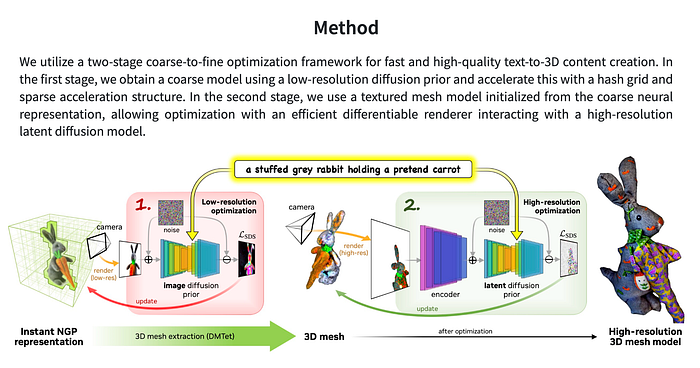
DreamFusion (Google)
DreamFusion is based on Google’s private 2-D image generation tool: Imagen, and Neural Radiance Fields (Nerf). Score distillation sampling (SDS) is used to turn the output of the diffusion model into a 3D model.

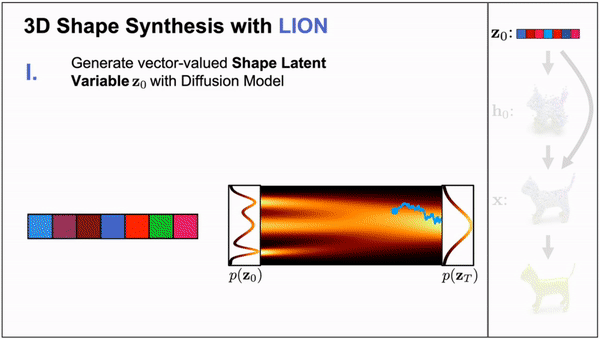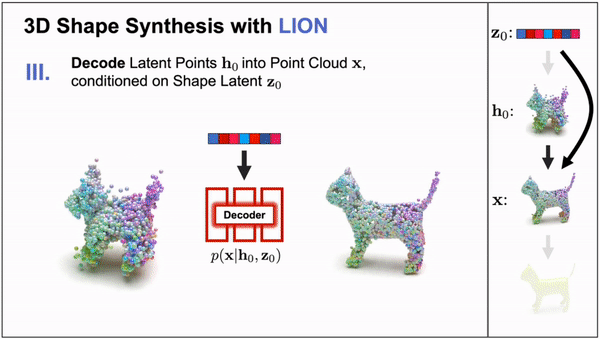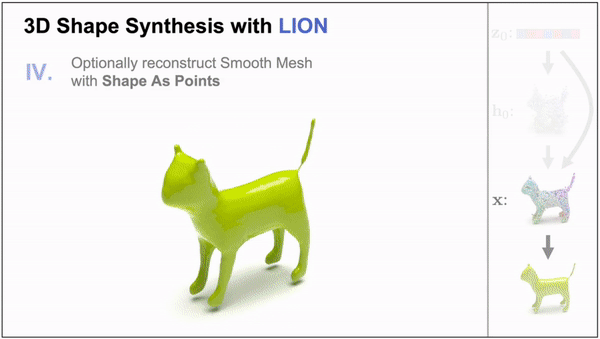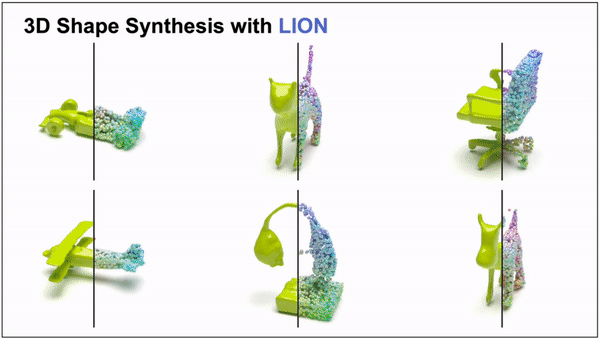
LION: Latent Point Diffusion Models for 3D Shape Generation (Nvidia)