A glimpse into the future of cinema: The ultimate guide to A.I. art for film/animation/VFX September 2022
What a great time to be alive! Human ingenuity, married with the speed of the parallel processors of A.I. is birthing a new way to create/produce art and motion pictures each day. Every day is a fact when I declare it; it is not just a question of speech. The generative A.I. community produces new findings so quickly that you may know something inside and out one day and be completely irrelevant the next. Hence, staying current with models, notebooks, and inventions requires ongoing research, development, and updating your Rolodex of resources. I plan to publish an article about the latest inventions and creative samples from the A.I. community regularly so that you do not need to do so. So be sure to follow my page to stay informed about all things creative A.I.
Obviously, A.I. offers many tools for film production, including reading/optimizing scripts for sales, distribution, editing (facial recognition), character creation, subtitles… This article, however, only focuses on cutting-edge artistic A.I. technologies that independent filmmakers are now experimenting with. Since most of these tools are open source, the entire creative A.I. community is contributing to their development, alongside the people who wrote them. Yes, they are not yet “big screen” ready because A.I. motion pictures are still in their infancy, but it won’t be long until these generative technologies become the love child of Hollywood and technology.
Deforum (Based on Stable Diffusion)
If A.I. art was the invention of photography, then A.I. used in film for VFX is like the discovery of sequencing celluloid films to make motion pictures. Recent months have seen a surplus of generative A.I. and notebooks of text-to-image based models and notebooks, such as Dalle2, Midjourney, Stable Diffusion… This notebook, Deforum, is based on Stable Diffusion (by Stability AI) and is helping us get one step closer to temporal coherence in animation.
Until Deforum (Stable Diffusion), artificial networks’ capacity to re-create famous actors has been wonky, but as you’ll see in Michael Carychao’s sample below, it is improving daily. In a couple of years, we’ll be able to write “Brad Pitt dancing like James Brown and be able to have a screen-ready coherent result. Crazy, I know. I told you… it s a great time to be alive!


Stable Diffusion Text-to-Image Checkpoints for Runway ML (coming soon)
My favorite way to use A.I. is when it helps me save from the 3Ds — dirty, dull, and dangerous. This is the perfect example. Patrick Esser, a research scientist at Runway ML Tweeted about this mind-bending VFX capacity that runs on Stable Diffusion that they will soon release in Runway ML.
Those that are avid readers of my Medium blog know that, the main point for humans to remain relevant in the age of A.I. (which is also the age of Aquarius, in other words, The Age of Consciousness) is to focus on WHY we are doing what we are doing, not the HOW. As in this VFX example, the machines will always handle the how. In the artisanal, the craft will be an option and no longer a requirement for the success of an oeuvre, a creation, or a motion picture.

Implementing A.I. into the Unreal Engine
If you are messing with A.I. and you work in VFX and/or you are in virtual production, let me guess, all you can think about is how to integrate A.I. into Unreal Engine. Rightfully so! Even if the possibilities for incorporating generative art models into UE (Unreal Engine) are limitless, people who have explored this area are few and far between.
The music group Sagans made it to UE newsletter when they implemented A.I. (Disco Diffusion 5 as a style, combined with, I am guessing, VQGAN) for their 3D landscapes and for their Meta Human character. Disco Diffusion clamps into details. As a result, if you have an empty wall or window, it will have difficulty generating visuals there. It will cling to the existing noise, such as the window frame or graffiti on the wall.

Another A.I. + UE experiment: Daniel Skaale, who works for Khora VR has posted this sample below, where he has carried a 2D image that he has created in midjourney into Unity HDRP. This is great, but generating in real-time in UE or HDRP is still an unexplored territory (as of September 1st 10am).

Thin Plate Spline Motion Model
Thin Plate Spline Motion Model is an improved version of First Order Motion Model. It enables you to animate any face or illustration of a face by guiding the image with a video (the face needs to have human properties and proportions). This model is relatively easy to work with. However it generates in 256 x 256 pixels so you need a good upscaler. At Seyhan Lee, we use Topaz Video Enhance A.I. for upscaling. The only tip we would give is to keep your head as still as possible when driving the input video.
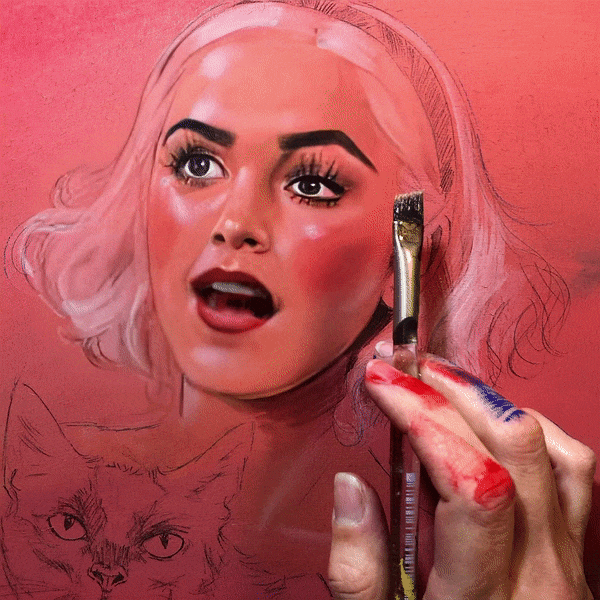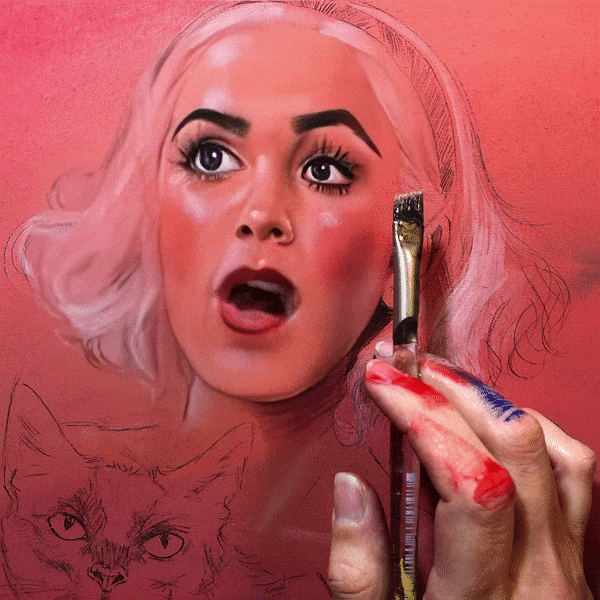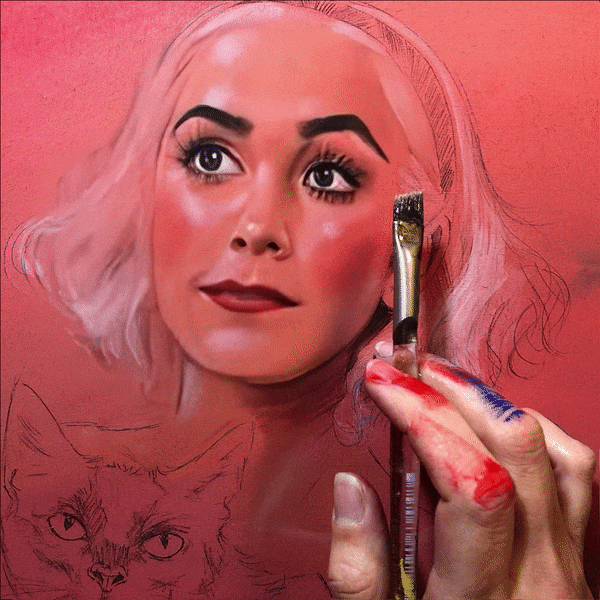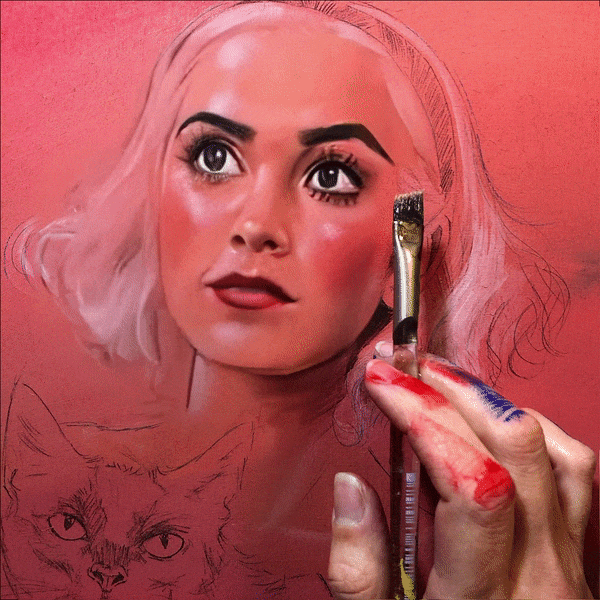
Dalle2 Inpainting Stop Motion
Dalle2, released by Open AI, allows the creators to generate creative images by guiding the networks only with words. The model does not offer motion picture sequences (yet!). However, with the magic wand of creativity, one can turn any still into motion. Director Paul Trillo has been creating really fun stop-motion Dalle2 frame-by-frame animations. If you want to implement this into your own project, follow this Twitter thread where he explains how it can be done.

Transfer of Style
Being able to manipulate space/time and human perception when working with A.I. art is one of the things that excites me the most. I predict that this way of letting A.I. re-create your footage in a style of your choice will be one of the first A.I. art tools that studios will adopt. Give it a couple of years, and you’ll be able to film a scene of 4 random people walking down an aisle, and you will be able to turn them into Dorothy and the gang in the Wizard of Oz. Arguably, you can do this right now, but it will be wonky, smudgy, and missing 8K details, so not ready for the mass audience.
There are two ways of transferring a style right now. One with a pre-defined style, for example, a Van Gogh painting, the other by using text-to-image based models such as Disco Diffusion and VQGAN+CLIP, where you guide the style with words, referred to as “prompts” in the community. These prompts are your most significant creative assets, and many people who make art with these text-to-image tools also call themselves “prompt artists”. Here is a fun publication that compiles prompts that work best with the Dalle2 model.
Style Transfer paper was initially released in 2015. By transforming the original image into that style, the Style Transfer notebook enables the creatives to specify a style, neural networks to learn that style, and them to recreate the image or motion picture by becoming that style. The difference from any other “texture” or “filter” we are used to in other creative tools is that you can be wildly more creative, more than any other linear filter tool. For example, you can visualize what it feels like to be consumed entirely by the flavor of Doritos, or give a live-action film an ambiance of arcane comics (see below).


When it comes to Disco Diffusion, because the model is released and maintained by a team of around 10 people, they are continually iterating on changes, adding tools such as optical flow, which produces the greatest “transfer of style” model, in my opinion. Diffusion models in general, produce more accurate/detailed images and have significantly more settings to work with. By being part of their Discord community, you can be up to date with this model.
The example below was made with Disco Diffusion 5.6 where we, the Seyhan Lee team, used “Romantic flowery pre-raphealite Korean fairy princess in a solarpunk empire.” as a prompt to guide the machine. As you’ll see, the optical flow, the coherence, and the detailing are far superior to the Style Transfer Doritos example I have given above.
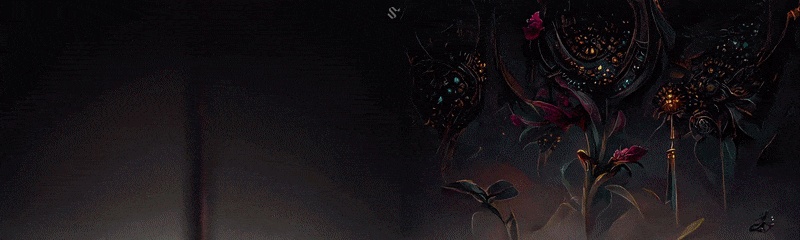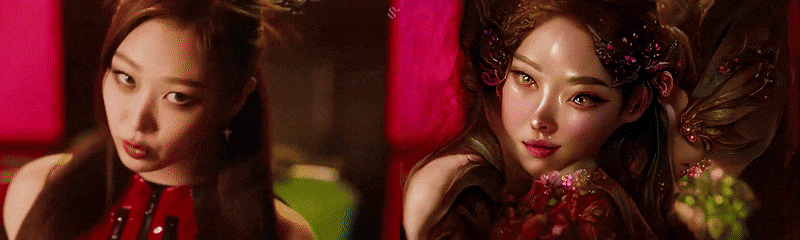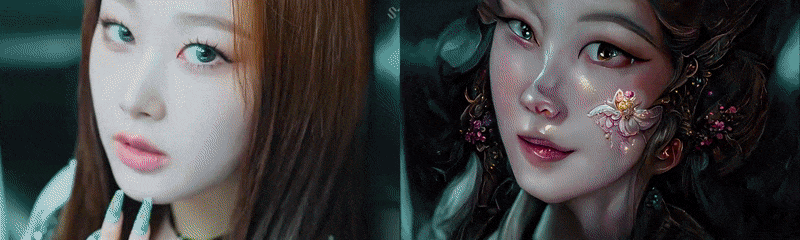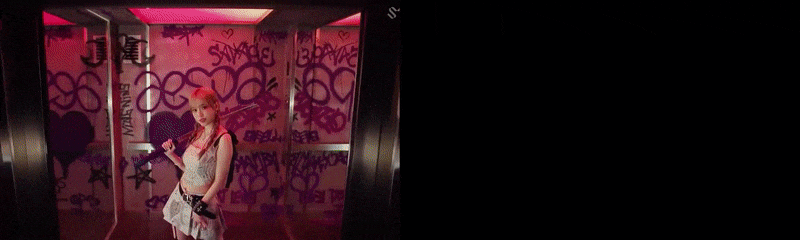
Another text-to-image-based transfer of style would be CLIP + VQGAN. This example below is made by Glenn Marshall. It is a sample from his movie “Crow”, which received the Jury Award at the Cannes Short Film Festival this year.

Impersonator / Deep Fake
I no longer know if I am doing you a service or if I am contributing to your nightmares tonight by sharing this video of Willem Dafoe as Julia Roberts in Pretty Woman. This video, made by @Todd_Spence probably with Reface App, gives us a glimpse into the future of how A.I. will help us optimize production to the nth degree. Soon, studios will simply need to rent Brad Pitt’s face value rights for him to appear in the upcoming blockbuster film without having to leave the comfort of his couch.
Of course, the Reface App is not ready to be used for high production; however, similar models such as Deep Fake, have been used continuously in the industry. For example, Roadrunner: A Film About Anthony Bourdain used Deep Fake for Anthony to say things he didn't, and this campaign for malaria made David Beckham speak languages he doesn't.

Style GAN, the OG!
And just when you thought I’d end this article without the OG of generative art, the infamous Style GAN. This model is credited as being one of the first attempts in humanity’s search to understand and create with generative models. I found myself in the center of A.I. art back in 2017. In those days, we only had Deep Dream, Feature Visualisation by distill.pub, Style Transfer, and Style GAN as models to play with when generating pictures with machine learning. I happened to direct the world’s first A.I. assisted music video, and I have selected the scientific hypothesis Panspermia as the theme. You guessed it, the whole video is made with two models: Style GAN & Style Transfer.
As an A.I. director, although a lot has changed since 2017, Style GAN is still one of my favorite ways to create motion picture sequences. There is something magical about seeing a static object, like a mountain, engage in a motion that you would only experience under visionary journeys such as psilocybin mushrooms or Ayahuasca. This example below is a VFX sequence we made at Seyhan Lee for Descending the Mountain film by Maartje Nevejan by creating a custom database of 20,000 mountains and training the machine for six weeks.

Style GAN also produces really impressive results with faces. Our dear friend and collaborator Jeremy Torman have been conducting fascinating experiments with people, cyborgs, and all things psychedelic.
As in any other technology which is in its infancy, A.I. art still misses temporal coherence, which is our capacity to make jumping jacks or walk down the street. Also, the ability to control the camera, and IRL physics… We are currently making creative expressions by changing shapes and pictures in motion. Right now, you can produce mind-bending, never-before-seen sequences with A.I., but you cannot do everything (yet). A.I. used in animation and in VFX is going nowhere. We are here and we are only growing. In a few years, we’ll be able to generate coherent and screen-ready full features that are entirely generated. If you are a producer, director, studio owner, or VFX artist who wants to stay ahead of the curve, now is the time to invest in this technology; otherwise, your competition will be generating headlines, not you.

Dear reader, thank you for taking the time to read this essay. These industry-changing novel ways of motion picture creation spread to others when you engage with my thoughts socially, so thank you for subscribing to my Medium channel and sharing this article with your following.
With love, Pinar
